-
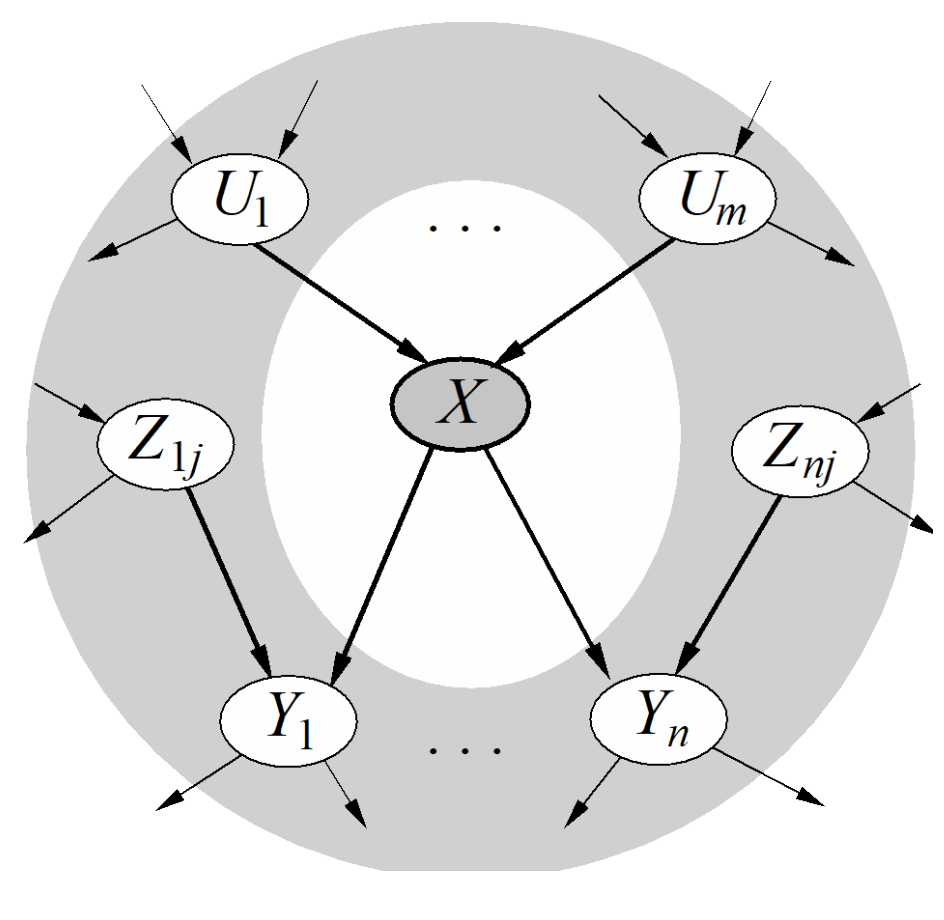
Bayesian Networks
Network Representation, D-Separation, Inference, Sampling
-
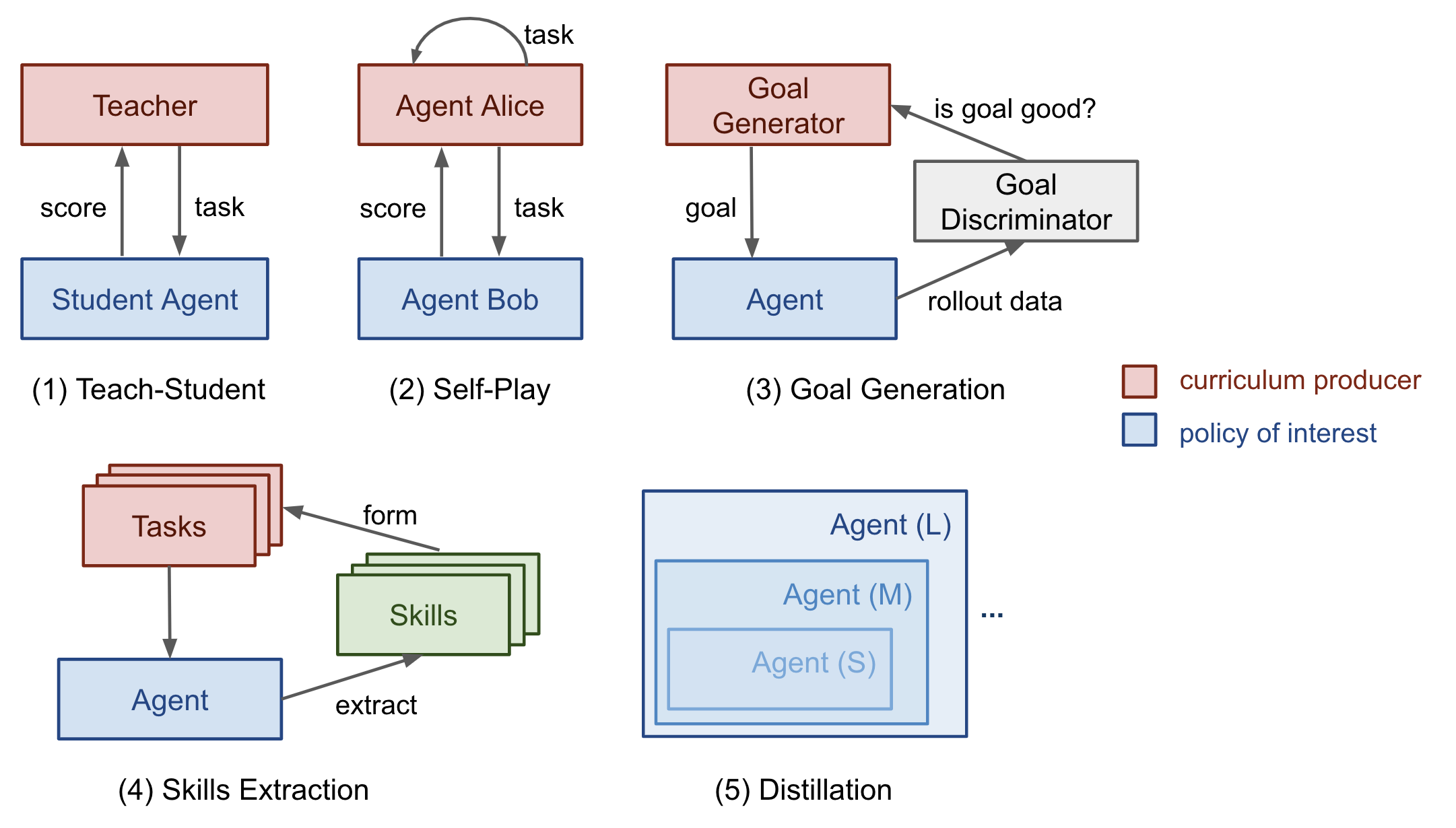
Curriculum Learning Methods
Task-Specific, Teacher-Guided, Self-Play, Automatic Goal Generation
-
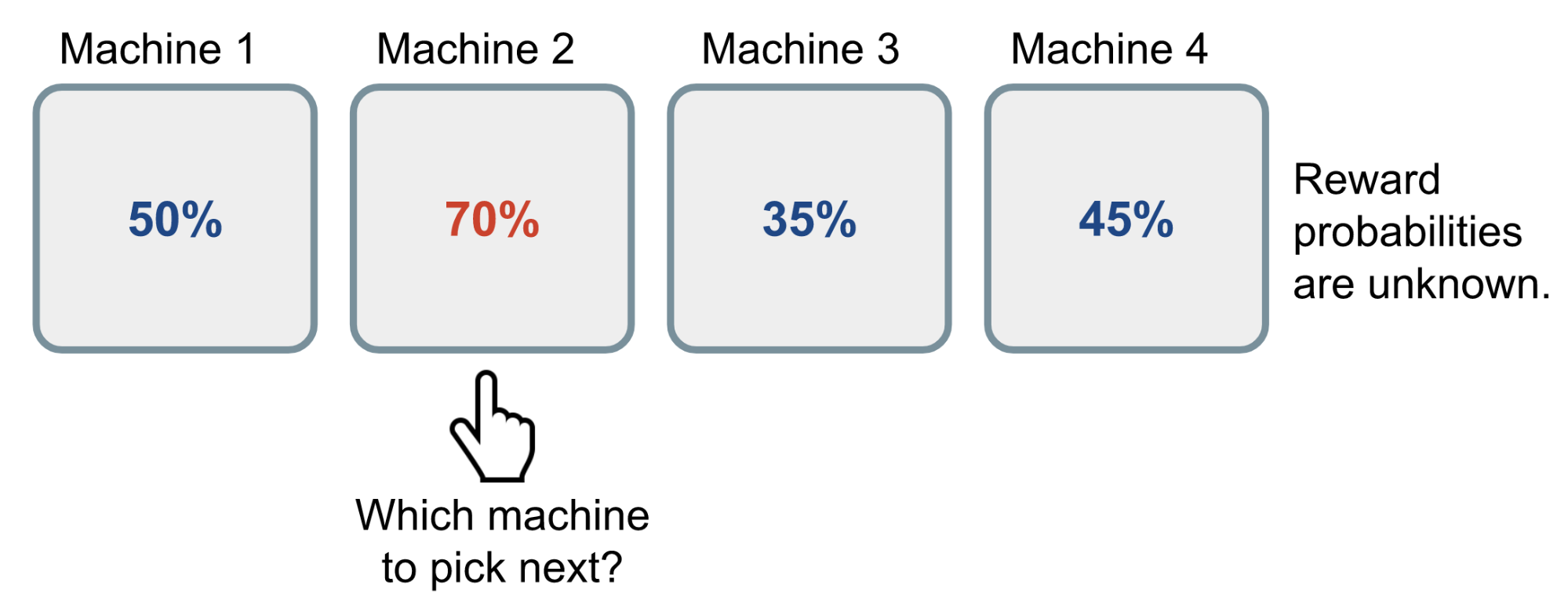
Multi-Armed Bandit Problems
Bandit Strategies, UCB1, Bayesian UCB, Thompson Sampling
-
Natural Policy Gradient Methods
General overview of TRPO and PPO
-
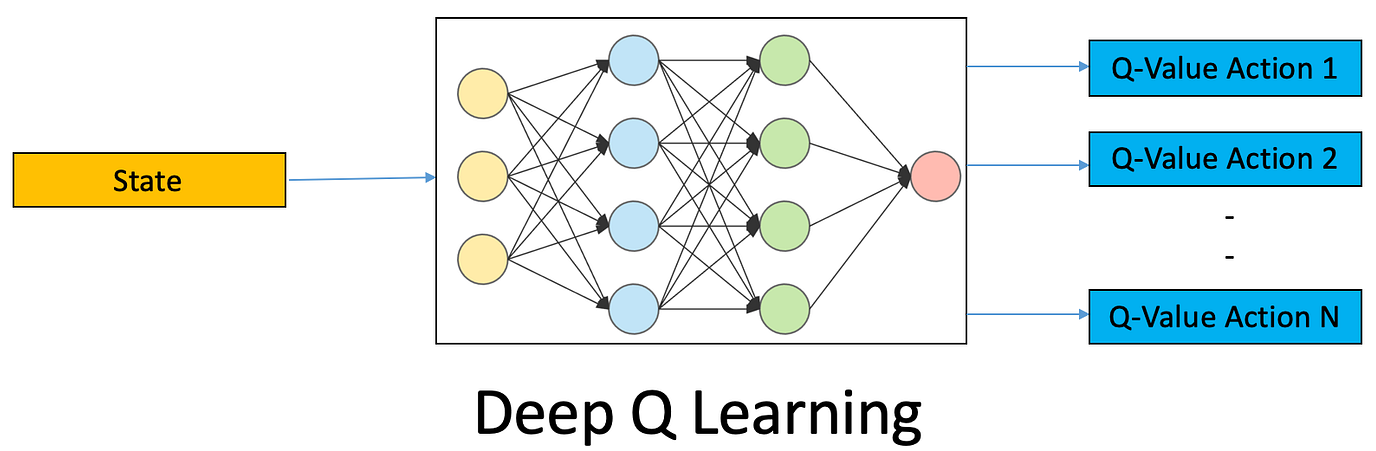
Deep Q-Learning
Double Q-Learning and Deep Q-Networks
-
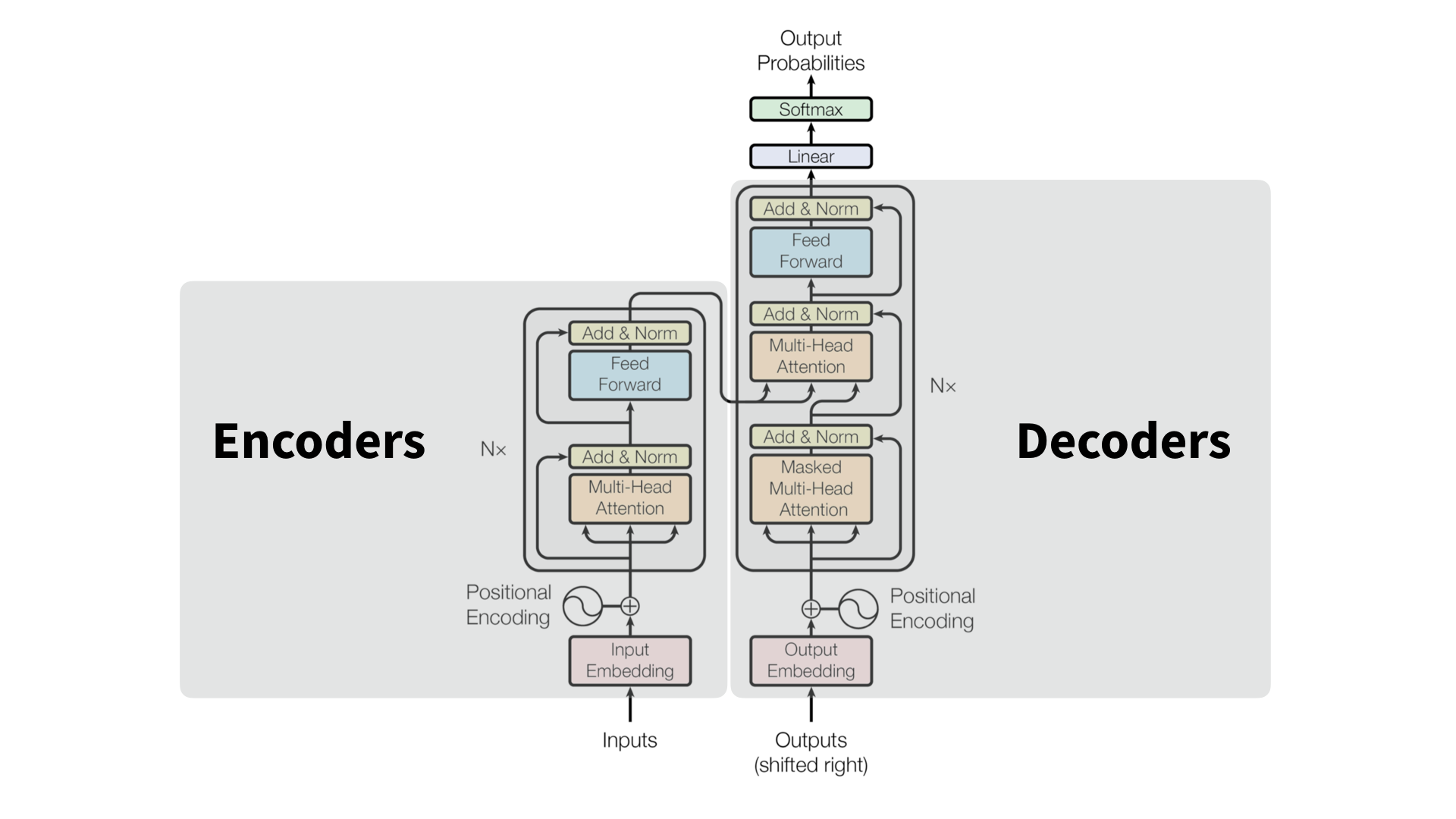
Transformer Architecture
Original design, BERT, GPT-1
-
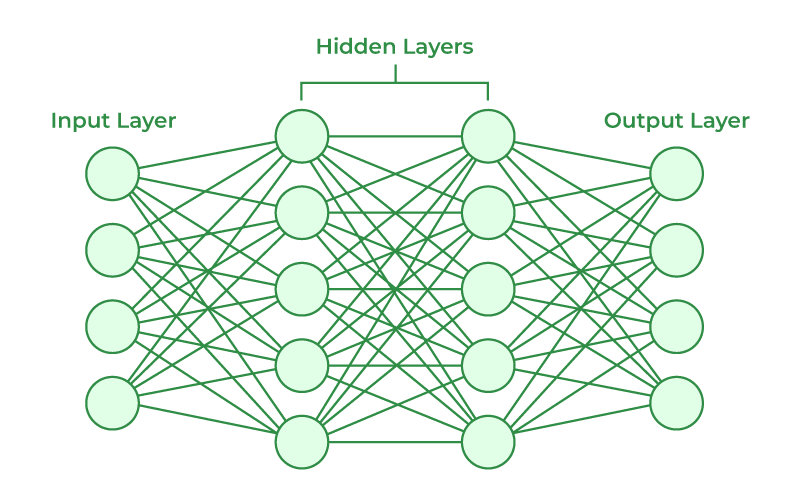
Deep Learning
Key concepts, FFNs, Sequence Models
-
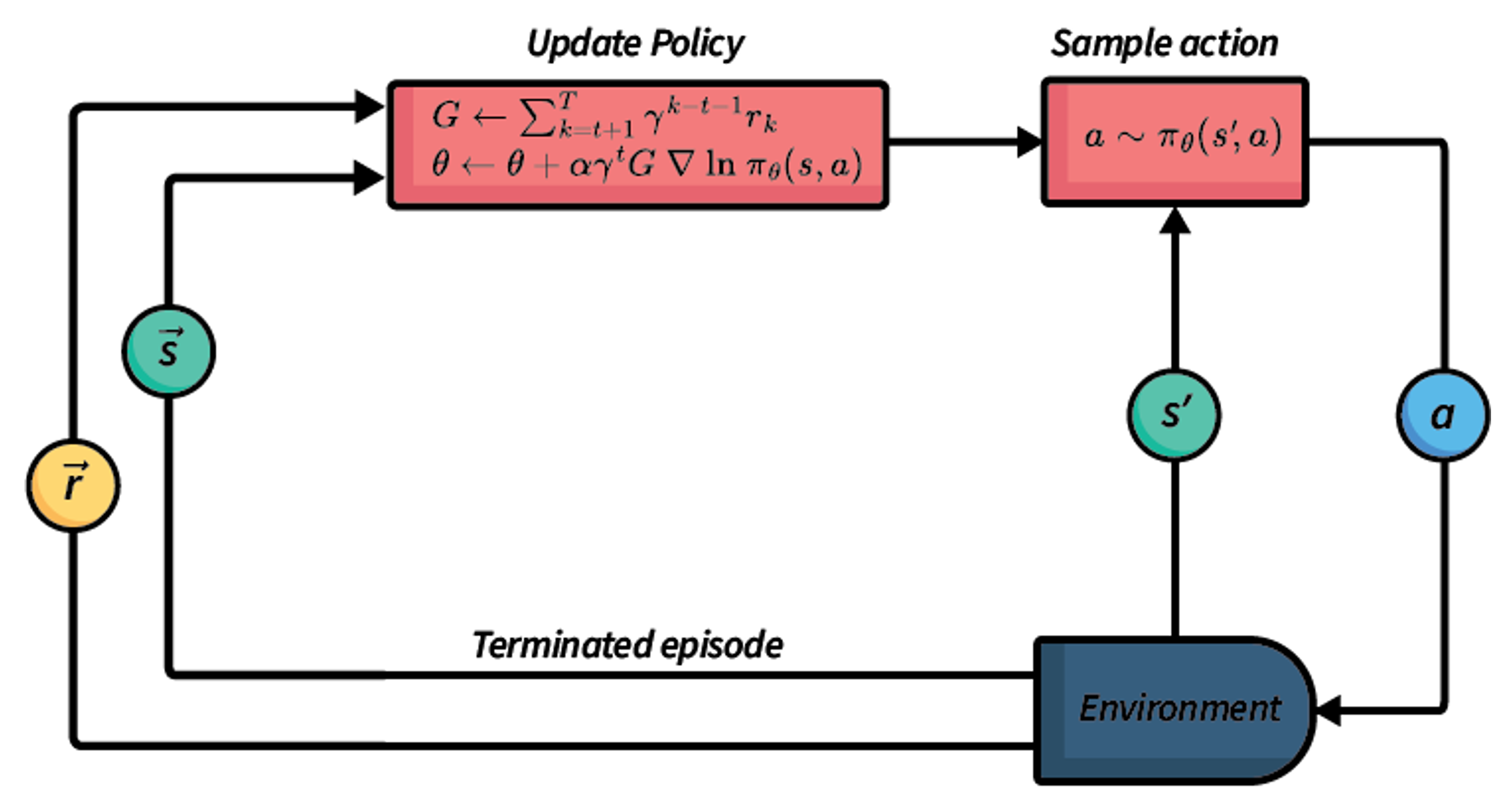
Vanilla Policy Gradient Methods
Theoretical foundations and REINFORCE
-
LLM Fine-Tuning Taxonomy
Supervised fine-tuning, reinforcement learning
-
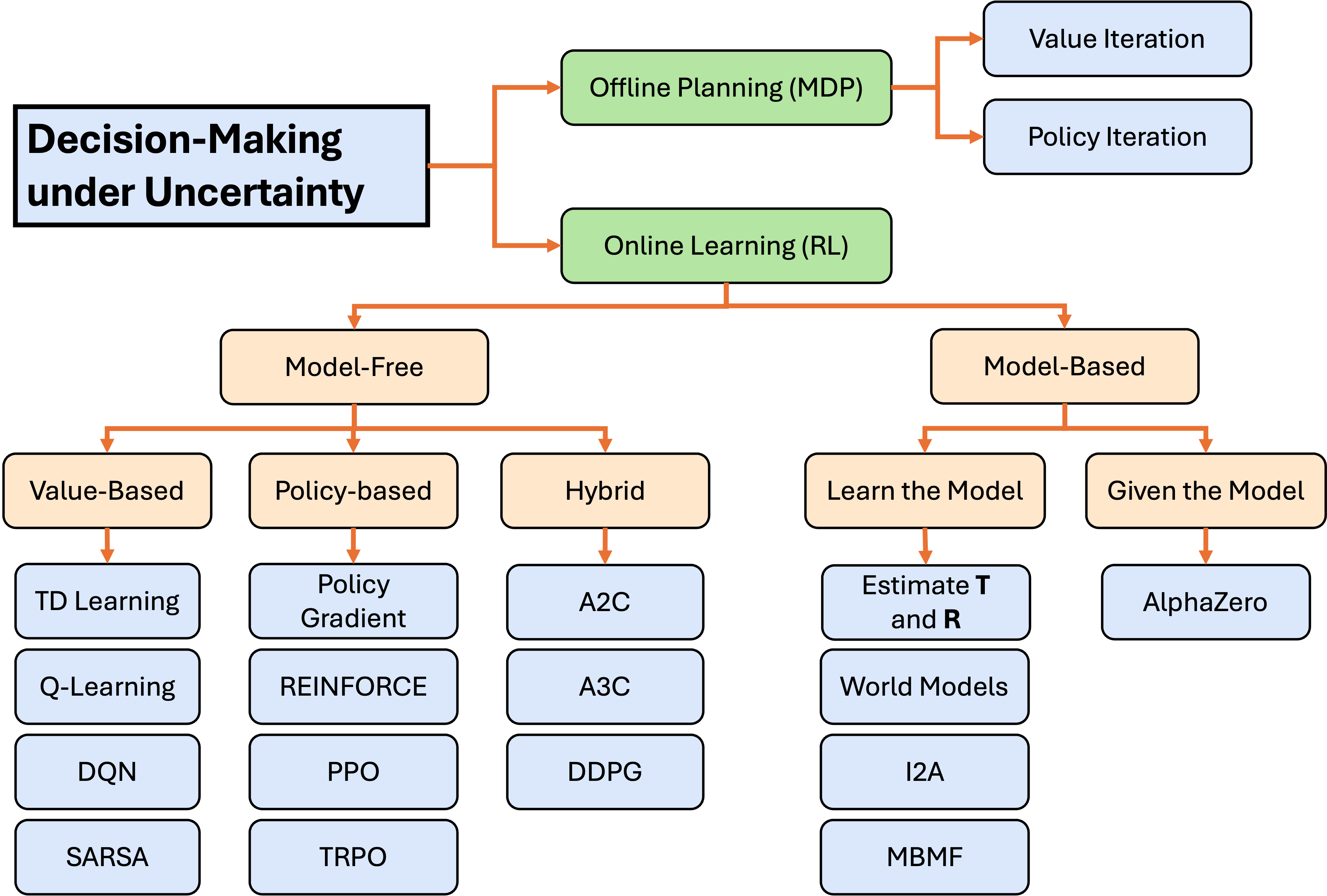
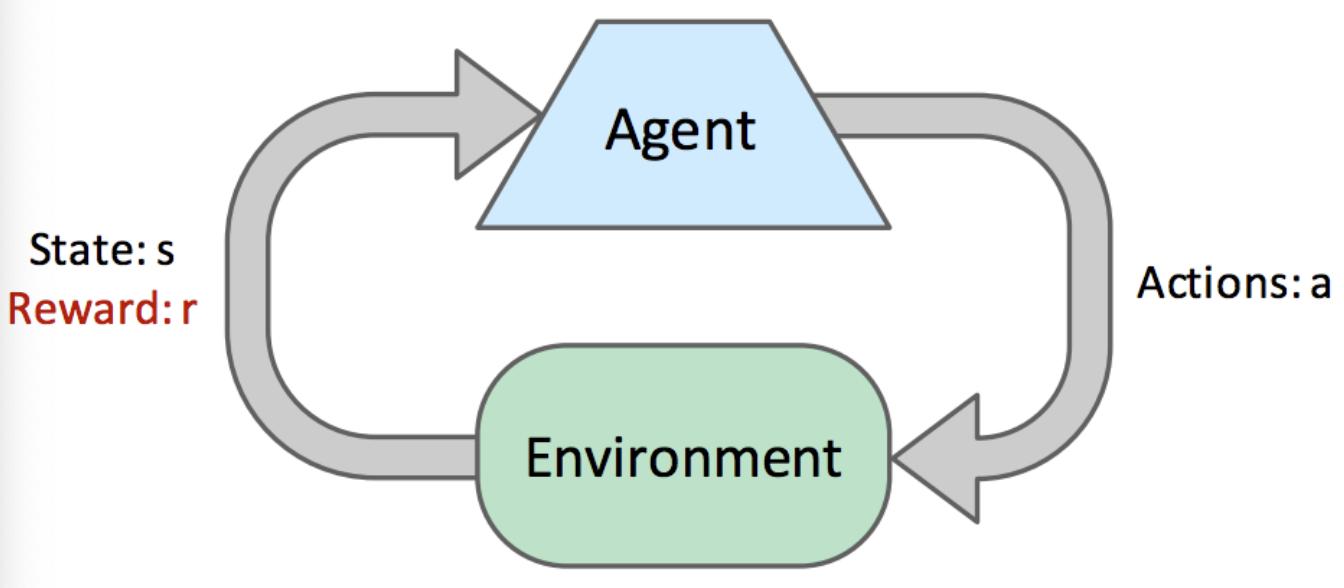
Reinforcement Learning
Model-based and Model-free learning (Direct, TD, Q-Learning)
-
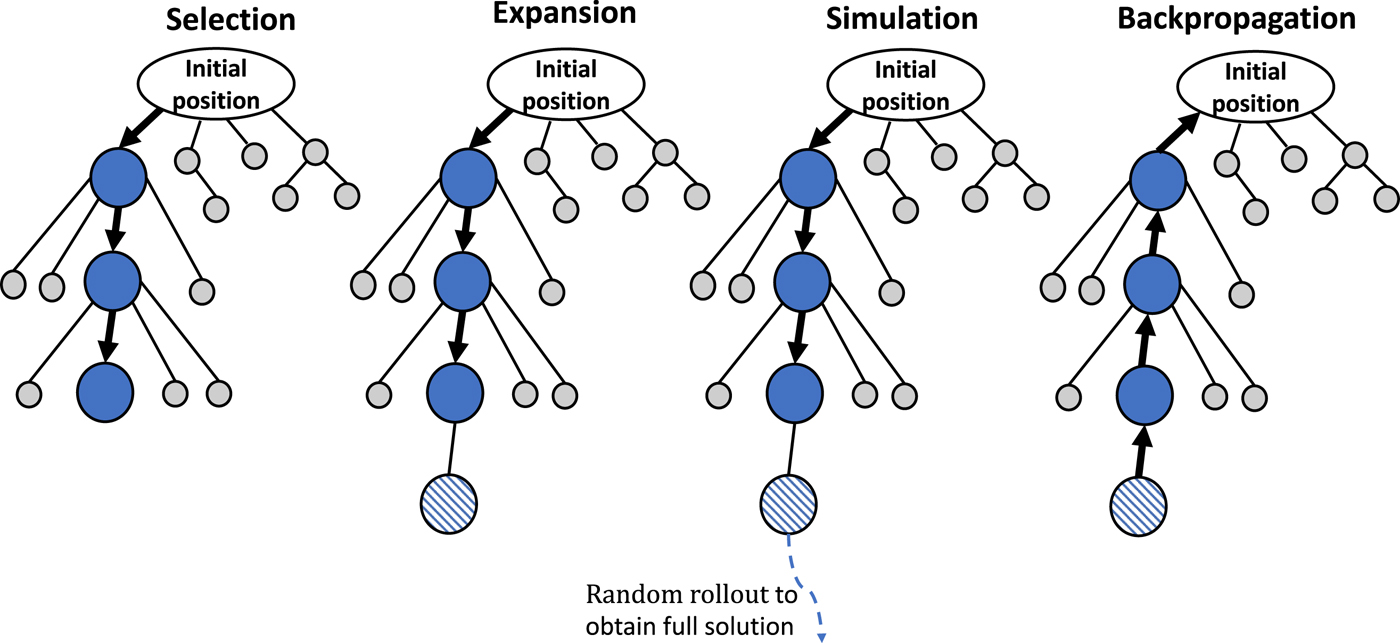
Adversarial Search Algorithms
Minimax, Expectimax, Monte Carlo Tree Search
-
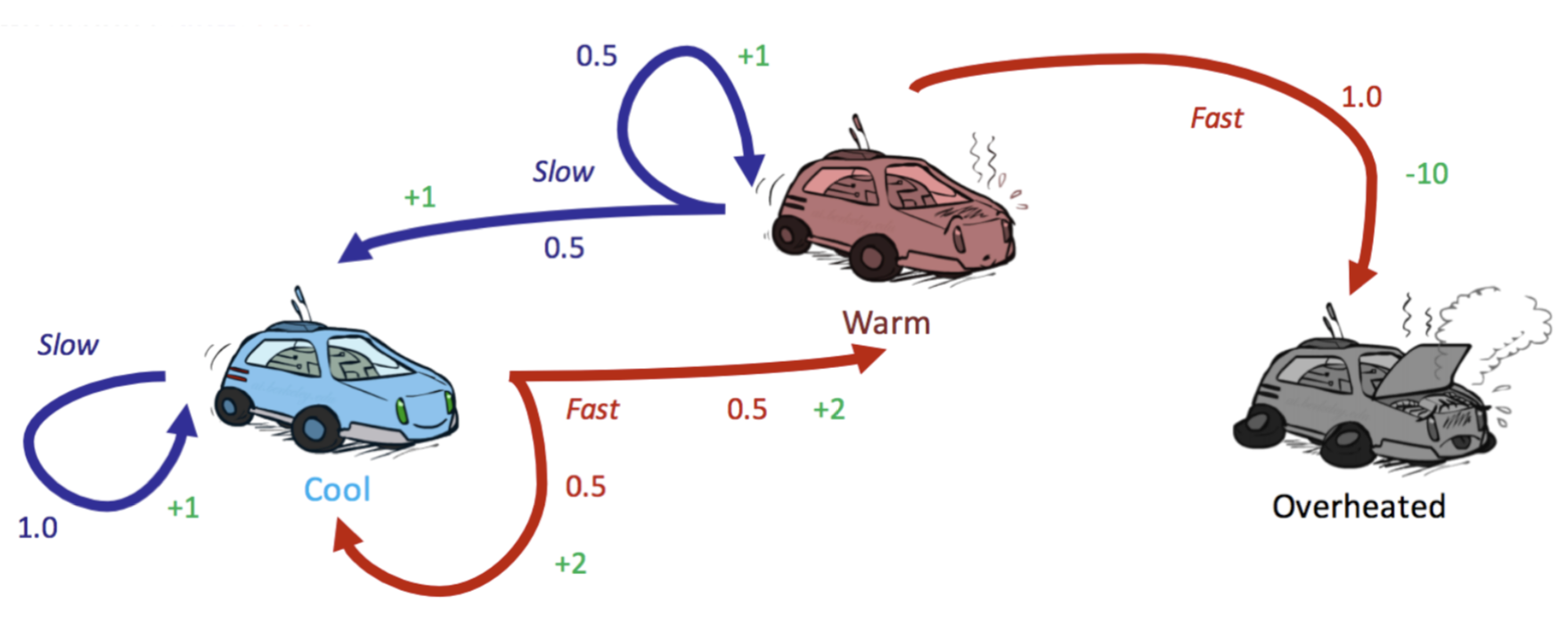
Markov Decision Processes
A general overview on Markov Decision Processes (MDP)
-
a post with pseudo code
this is what included pseudo code could look like